Original description:
Prove that you are a robot, build all the curves and send me an answer! P.s. base64.b85encode(bz2.compress(txt.encode())).decode(“UTF-8”) nc tasks.aeroctf.com 40001
Problem:
You need to get the formula from the server, plot it and then solve the capcha in the plot.
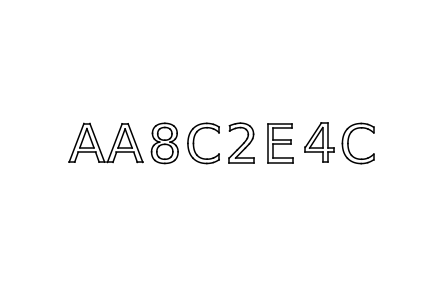
Once plotted, segmented and isolated, the letters to learn look like this:


Solution
Similar to funny-pictures. Most code is copied.
- Connect to the server via nc and get a list of curve-formulas
- Eval each curve formula with x = 0..100 -> the results are x/y values
- Plot these x/y values and get hollowed out numbers
- Implement a bounding box check, that only the biggest bounding boxes count (0 has a smaller 0 in the middle)
- Train another model to recognize hollowed out 0-9A-F letters again
Code Runner
import base64
import bz2
import numpy as np
import matplotlib.pyplot as plt
from io import BytesIO
from PIL import Image, ImageFilter, ImageOps
import tesserwrap
import os
from skimage import measure
from collections import Counter
import tensorflow.keras as keras
model = keras.models.load_model("model.keras")
%env TERMINFO=/usr/share/terminfo
%env PWNLIB_NOTERM=true
from pwn import *
# tr = tesserwrap.Tesseract()
# tr.set_variable("tessedit_char_whitelist", "0123456789ABCDEF")
def classify(letter):
global model
letter = np.array(letter.getdata(), dtype=np.float32).reshape((1,28,28,1))
return "0123456789ABCDEFG"[np.argmax(model(letter))].replace("G", "")
def detect(img):
img = ImageOps.invert(img.convert("L", colors=1))
for i in range(img.width):
for j in range(img.height):
col = 255 if img.getpixel((i,j)) > 128 else 0
img.putpixel((i,j), col)
#plt.imshow(img, cmap="gray"); plt.show() # debug: show image
all_labels = measure.label(np.array(img), background = 128) # segment image
# plt.imshow(all_labels); plt.show() # debug: show image
text = dict()
# create a list of only the letters being 1, ignore the background with >10000 pixels
letters = [all_labels == color for color, cnt in Counter(all_labels.reshape(-1)).items() if cnt < 10000]
positions = [list(np.where(letter)) for letter in letters]
for letter, position in zip(letters, positions):
pad = 2 # padding
minx = min(position[0])
maxx = max(position[0])
miny = min(position[1])
maxy = max(position[1])
# skip very small items as they are probably an error
size = (maxx-minx)*(maxy-miny)
if size < 100:
continue
q = False
for position2 in positions:
pminx = min(position2[0])
pmaxx = max(position2[0])
pminy = min(position2[1])
pmaxy = max(position2[1])
if minx in range(pminx, pmaxx) and maxx in range(pminx, pmaxx) and \
miny in range(pminy, pmaxy) and maxy in range(pminy, pmaxy) and not \
(pminx == minx and pmaxx == maxx and pminy == miny and pmaxy == maxy):
q = True
if q: continue
sub_image = np.array(img)[minx:maxx, miny:maxy].astype(np.uint8)
pil_image = Image.fromarray(sub_image > 0).resize((28,28))
# plt.imshow(sub_image, cmap="gray"); plt.show(); # for debugging initial digits
# text[miny] = tr.ocr_image(pil_image) # didn't fully work for me
text[miny] = classify(pil_image)
pil_image.save(f"letters/{text[miny]}/{random.random()}.png") # collect data to improve/retrain the classifier
detected = "".join([text[pos] for pos in sorted(text)])
#plt.imshow(img, cmap="gray"); plt.show(); print(detected)
return detected
r = remote("tasks.aeroctf.com", 40001)
r.send("Y\n")
r.recvline();
while True:
line = r.recvline().decode("UTF-8").replace("Result: ", "").replace("Ready? <Y/n>", "").replace("\n", "")
#print(line)
fig, axs = plt.subplots(1,1)
axs.axis('equal')
curves = bz2.decompress(base64.b85decode(line)).decode("UTF-8")
for line in curves.split("\nf(t) = ")[1:]:
code = line.replace("^", "**").replace(";", ",").replace("{", "(").replace("}", ")")
xx, yy = [], []
for i in range(0, 101):
t = i / 100
x, y = eval(code)
xx.append(x); yy.append(y)
plt.plot(xx, -np.array(yy), "k")
axs.set_axis_off()
#buf = BytesIO()
buf = "tmp.png"
plt.savefig(buf,)
img = Image.open(buf)
text = detect(img)
print(text)
r.send(text+"\n")
Code build model
from __future__ import print_function
import tensorflow.keras as keras
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras import backend as K
from tensorflow.keras.utils import to_categorical
import os
import numpy as np
import random
from PIL import Image
batch_size = 64
num_classes = len(os.listdir("letters"))
epochs = 100
# input image dimensions
img_rows, img_cols = 28, 28
signs = "0123456789ABCDEF"
def load_data():
trainx, testx, trainy, testy = [], [], [], []
for dir in os.listdir("letters"):
for file in os.listdir("letters/"+dir):
img = Image.open("letters/"+dir+"/"+file)
img = np.array(img.getdata())
id = signs.index(dir)
if random.random() < 0.9:
trainx.append(img); trainy.append(id)
else:
testx.append(img); testy.append(id)
return (np.array(trainx), trainy), (np.array(testx), testy)
# the data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(learning_rate=0.1),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
model.save("model.keras")
print('Test loss:', score[0])
print('Test accuracy:', score[1])